Roofing
- Usman Arshad
- Dec 29, 2025
- 9 min read
Стратегии Клиентского Сервиса: Оптимизация Клиентского Опыта через LLM и Автоматизацию

Качество клиентского сервиса напрямую влияет на удержание, лояльность и экономическую эффективность компании; современные LLM и автоматизация меняют правила взаимодействия, позволяя сочетать масштабируемость с персонализацией. В этой статье читатель получит практическое руководство по внедрению стратегий клиентского сервиса, которые повышают CSAT, сокращают время решения и уменьшают усилия клиентов, используя LLM, долговременную память и RAG. Мы рассмотрим этапы внедрения, технические архитектуры памяти, ключевые технологии и интеграции с CRM, а также метрики, через которые измеряется ROI LLM в CX. Проблема большинства проектов — потеря контекста и непоследовательность ответов при длительных взаимодействиях; решение — гибридные подходы к памяти и векторные БД с ретривером. Дальше по разделам мы пройдем от определения целей UX до выбора RAG-архитектуры и конкретного пошагового плана внедрения, вплоть до показателей эффективности.
Как внедрить Стратегии Клиентского Сервиса для максимального UX?
Внедрение стратегий клиентского сервиса начинается с четкого определения целей UX: какие метрики вы хотите улучшить и почему это важно для бизнеса. Механизм работы включает согласование KPI, проектирование омниканальных сценариев и интеграцию LLM/автоматизации для поддержки повторяющихся задач, что даёт конкретный эффект на CSAT и время решения. Практический план уменьшает неопределённость и ускоряет пилотирование, поэтому следующая часть приведёт пошаговый список действий. Ниже — структурированный набор шагов, применимый для старта пилота и масштабирования.
Ниже — ключевые шаги для внедрения, которые подходят для большинства команд, стремящихся к улучшению UX и эффективности.
Определите цели UX и KPI: CSAT, NPS, CES и целевые уровни для них.
Спроектируйте омниканальные пути: карты customer journey и SLA для быстрых решений.
Подготовьте данные и интеграции: CRM, история взаимодействий и knowledge base.
Выберите архитектуру памяти: RAG, fine-tuning или гибридный подход для LLM.
Запустите пилот, измерьте метрики, скорректируйте сценарии и масштабируйте.
Этот пошаговый план даёт структуру для быстрого старта: начинать с целей и данных, затем переходить к технологиям и итерациям, что естественно ведёт к обсуждению конкретных основ оптимизации UX.
Определите цели UX: CSAT, NPS, CES

CSAT, NPS и CES — это центральные целевые метрики UX, каждая измеряет отдельный аспект опыта и требует собственной методики сбора данных. CSAT фиксирует удовлетворённость по конкретному взаимодействию через опросы после тика, NPS показывает склонность к рекомендации бренда и даёт стратегический индикатор лояльности, а CES измеряет усилия клиента для решения задачи и прямо коррелирует с оттоком. Формулы просты: CSAT — процент положительных ответов; NPS = % промоутеров − % детракторов; CES — средний балл усилий; все они помогают задать целевые пороги и приоритизировать улучшения. Понимание этих метрик логически переходит в проектирование омниканальных сценариев, где снижение CES и повышение CSAT реализуются через оптимизированные пути клиента.
Стройте омниканальные сценарии и быстрые пути
Омниканальность — это дизайн согласованного пути клиента через все точки контакта, где переключение между каналами не ломает контекст взаимодействия и снижает число повторных объяснений. Практическая механика включает map customer journey, определение точек переключения, SLA для ответа и автоматические триггеры для эскалации, а также интеграцию чат-ботов с CRM для передачи состояния. Для проектирования пригодятся чек-листы с обязательными данными и критериями переключения, которые обеспечат предсказуемость и скорость. Корректное проектирование сценариев ведёт к техническим требованиям — какие данные и инструменты нужны для реализации автоматизации и хранения истории клиента.
Какие основы Оптимизации Клиентского Опыта дают наибольший эффект?
Оптимизация CX базируется на нескольких принципах, которые дают наибольший эффект при системном применении: персонализация, снижение усилий клиента (CES), стабильность и последовательность ответов, а также обучение персонала и стандарты качества. Механизмы реализации включают использование эмбеддингов для персонализации, RAG для последовательности и автоматические шаблоны ответов для стабильности, что сокращает вариативность сервиса и повышает CSAT. Ключевые практики комбинируют технологические меры и процессные стандарты: регулярные тренинги, контроль качества диалогов и анализ тональности, чтобы быстро закрывать проблемные точки. Переход от принципов к технологиям естественным образом требует обсуждения LLM и долговременной памяти как центральных инструментов, способных сохранить контекст и персонализацию.
Персонализация взаимодействий: использование профилей и истории для релевантных ответов.
Снижение усилий клиента: минимизация шагов до решения, упор на CES.
Стабильность и последовательность: единые ответы и стандарты обслуживания.
Обучение персонала: регулярные тренинги и скрипты качества.
Эти принципы формируют основу практических архитектур и технологических выборов, о которых пойдёт речь далее.
Как LLM и Долговременная Память для ИИ улучшают обслуживание клиентов?
LLM с долговременной памятью решают ключевую проблему — ограниченность контекстного окна, которая приводит к «забыванию» истории клиента и непоследовательным ответам. Механизм работы состоит в извлечении релевантных фрагментов истории из внешней памяти через ретривер, объединении их с текущим prompt'ом и генерации ответа, что повышает персонализацию и сокращает время решения. Конкретные выгоды включают последовательность в многосессионных взаимодействиях, лучшую персонализацию рекомендаций и снижение нагрузки на операторов за счёт автоматизации рутинных задач. Ниже дана сравнительная таблица подходов к памяти LLM, чтобы выбрать оптимальный путь для конкретного проекта.
Перед таблицей поясним цель сравнения: показать критические различия между RAG, fine-tuning и гибридными подходами по latency, стоимости, консистентности и персонализации.
Подход | Критерий | Оценка/Комментарий |
RAG (retrieval augmented generation) | latency | Низкая до средней при оптимизированной векторной БД; хорош в персонализации |
Fine-tuning | cost | Высокие начальные затраты, мала гибкость при изменении знаний |
Гибридный (RAG + fine-tuning) | consistency | Высокая консистенция + возможность быстрой подстройки; баланс затрат |
Эта таблица показывает, что RAG обеспечивает гибкость и персонализацию при управляемых задержках, тогда как fine-tuning даёт плотную интеграцию знаний, но менее оперативен при обновлениях. После выбора подхода важно понять технические детали контекстного окна и внешней памяти.
Понимание контекста: контекстное окно vs долговременная память
Контекстное окно LLM — это объём входных токенов, который модель учитывает при генерации; его ограниченность приводит к потере ранее предоставленной информации в длинных диалогах. Внешняя долговременная память решает эту проблему, сохраняя структурированную историю и извлекая релевантные куски через векторный поиск и эмбеддинги, что позволяет LLM «видеть» важную историю без перегрузки контекстного окна. Примеры ошибок при отсутствии памяти: повторные запросы информации, противоречивые рекомендации и потеря персональных предпочтений клиента. Понимание этой разницы оправдывает архитектуры RAG и vDB, которые мы обсудим дальше в разделе про выбор RAG-архитектуры.
RAG как решение для запоминания истории клиента
Retrieval Augmented Generation объединяет два компонента: ретривер (поиск по эмбеддингам во внешней базе) и генератор (LLM), который формирует ответ, используя извлечённые фрагменты как дополнительный контекст. Рабочий поток включает векторизацию новых документов/сессий, индексирование в векторной БД и быстрый ретривальный запрос при каждом обращении клиента. Преимущества RAG — масштабируемость, поддержка омниканальности и персонализация, а ограничения — необходимость управления качеством источников и latency при большом объёме данных. Переход к практическим технологиям требует выбора конкретных инструментов и интеграций с CRM и KMS.
Какие технологии и данные поддерживают Автоматизацию Обслуживания Клиентов?
Набор технологий для автоматизации CX включает LLM-ассистентов, векторные базы данных, эмбеддинги, платформы оркестрации, инструменты мониторинга KPI и интеграции с CRM и KMS. Типы данных — телеметрия, логи, история взаимодействий, FAQ и профили пользователей — формируют источник правды для ретривера и персонализации. Интеграция этих систем должна учитывать требования безопасности, время отклика и качество данных, чтобы автоматизация действительно поддерживала SLA и снижала CES. Ниже — практический перечень ключевых технологических компонентов и их роли в автоматизации.
Чат-боты и виртуальные ассистенты на базе LLM для автоматических ответов и маршрутизации.
Векторные базы данных и эмбеддинги для хранения и поиска контекстных фрагментов.
CRM и KMS как центральные источники клиентских данных и знаний.
Эта технологическая связка обеспечивает быстрые и персонализированные ответы; далее важно понять, как именно интегрировать чат-ботов с CRM и какие данные необходимы.
Чат-боты, автоматизация процессов и интеграции с CRM
Практическая интеграция чат-ботов с CRM предполагает передачу событий: создание/обновление кейса, запись истории взаимодействий, синхронизация статусов и триггеры для эскалации. Необходимые данные из CRM включают профиль клиента, историю покупок, открытые тики и заметки агентов; эти данные корректируют ретривер и повышают релевантность ответов. Требования к безопасности включают шифрование, контроль доступа и аудит действий, особенно при обработке персональных данных. Корректная интеграция ускоряет решение запросов и плавно ведёт к выбору RAG-архитектуры и векторных БД для обеспечения нужной производительности.
Как выбрать RAG-архитектуру и Векторные Базы Данных для вашего CX?
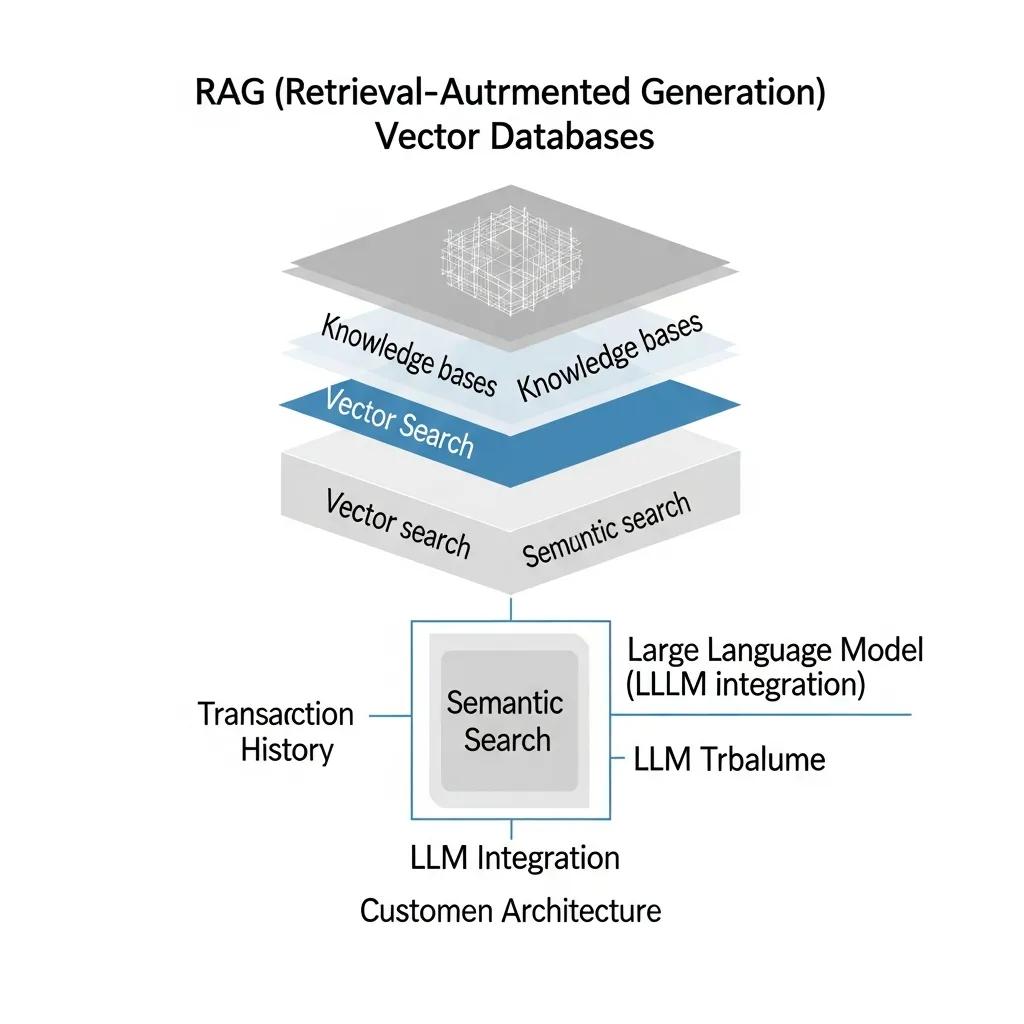
Критерии выбора RAG-архитектуры и векторной базы включают источники данных, latency, масштабируемость, стоимость и требования к консистентности. Источники данных влияют на стратегию индексирования: частые обновления — инкрементальные индексы, статичные документы — бэч-индексация. Latency критично для реального времени: цель — получить ретривал <200–300 мс для большинства случаев, что диктует выбор векторной БД и распределение ресурсов. Ниже представлена таблица сравнения популярных векторных баз по ключевым характеристикам и рекомендованному применению.
Перед таблицей поясним, что сравнение ориентировано на latency, масштабируемость и интеграции, чтобы помочь выбрать между опенсорсными и облачными решениями.
Векторная БД | Ключевые характеристики | Рекомендованное применение |
Qdrant | масштабируемость, поддержка фильтров | под гибридные решения с контролем над данными |
Milvus | высокая производительность, распределённость | большие наборы эмбеддингов и аналитика |
Pinecone (примерный) | простота управления, SLA | быстрый запуск облачного RAG-проекта |
Эта сводка показывает компромиссы между контролем, производительностью и простотой; после выбора платформы важно настроить параметры latency и резервирования для поддержания SLA.
Ключевые критерии выбора: источники данных, latency, масштабируемость
При выборе учитывайте качество и частоту обновления источников данных, допустимый latency для пользовательского опыта и требования к масштабируемости в пиковые нагрузки. Чек-лист включает: наличие аудита и версионирования данных, способность векторной БД обрабатывать миллионы эмбеддингов, опции репликации и аварийного восстановления. Практические пороговые значения: ретривал <200–300 мс для большинства интерактивных сценариев и способность обновления индекса в течение минут для оперативных изменений. Эти критерии логично выводят к необходимости тестирования архитектуры в пилоте перед масштабированием.
Какие Метрики CX и ROI показывают ценность внедрения LLM-помощников?
Для оценки эффективности внедрения LLM в CX ключевые метрики — CSAT, NPS, CES и FCR — дают разные перспективы: удовлетворённость, лояльность, усилия клиента и полноту решения на первом контакте. Связь с ROI проявляется через экономику: сокращение среднего времени решения (TTR), снижение cost per ticket и увеличение удержания клиентов повышают денежный эффект внедрения. Ниже приведена таблица метрик с их описанием и примером расчёта/целевого значения, чтобы показать, как анализировать эффект LLM.
Ниже таблица, объясняющая назначение каждой метрики и практические формулы для расчёта.
Метрика | Что измеряет | Как рассчитывать / Цель |
CSAT | Удовлетворённость конкретного взаимодействия | % положительных ответов; цель 80%+ в B2C |
NPS | Лояльность и рекомендация | % промоутеров − % детракторов; цель >30 |
CES | Усилие клиента | Средний балл усилий; цель минимизация на 20% |
FCR | Решение при первом контакте | % тиков закрытых при первом обращении; цель 70%+ |
Понимание этих метрик помогает связать изменения в процессах и технологиях с денежными показателями и формирует основу для расчёта ROI.
Основные метрики: CSAT, NPS, CES и FCR
CSAT показывает оперативную реакцию клиента на конкретное взаимодействие и быстро реагирует на изменения в сценариях; NPS отражает долгосрочное влияние на лояльность, а CES указывает на трения в процессе, которые приводят к оттоку. FCR критично для операционной эффективности: высокий FCR снижает нагрузку на контакт-центр и cost per ticket. После внедрения LLM-ассистентов ожидается снижение CES и TTR, рост FCR и улучшение CSAT, что в сумме повышает ROI LLM в CX и оправдывает первоначальные инвестиции. В следующем разделе разберём конкретные шаги внедрения от диагностики до масштабирования.
Какие шаги к внедрению: Пошаговый Plan для внедрения Стратегий Клиентского Сервиса с LLM?
Пошаговый план внедрения LLM в клиентский сервис состоит из трёх больших этапов: диагностика и целеполагание, проектирование архитектуры памяти и технологий, пилотирование и масштабирование. Каждый этап имеет чек-листы задач и критерии успешности: от сбора данных до измерения метрик пилота и решений о полном развёртывании. Такой поэтапный подход снижает риски и позволяет корректировать архитектуру по фактическим данным и метрикам. Ниже приведён упрощённый roadmap с основными шагами для запуска и итеративного улучшения.
Диагностика процессов и определение KPI для пилота.
Проектирование RAG-архитектуры, выбор векторной БД и интеграций с CRM.
Запуск пилота, сбор метрик (CSAT, CES, FCR), анализ и итерации до масштаба.
Такой пошаговый roadmap логично следует из анализа метрик и архитектурных решений и ведёт к последней части — детализированным этапам первого и второго шага.
Этап 1: Диагностика и целеполагание
Первый этап включает аудит текущих CS-процессов, определение целевых KPI и сбор входных данных: логи, записи разговоров, FAQ и структура CRM. Методика аудита — картирование customer journey, анализ горячих точек с высоким CES и вычисление baseline по CSAT/NPS/FCR. Результатом должны стать чёткие цели пилота, требования к latency и список приоритетных сценариев для автоматизации. Эти результаты служат основой для проектирования архитектуры памяти и выбора технологий на следующем этапе.
Этап 2: Архитектура памяти и выбор технологий
На втором этапе проектируется RAG-архитектура: выбор ретривера, векторной базы и стратегии индексирования; определяется схема эмбеддингов и порядок обновления данных. Критерии выбора поставщиков включают совместимость с CRM, требования к безопасности и SLA latency; план миграции данных предусматривает версионирование и тестирование на тестовой нагрузке. Также на этом этапе разрабатываются планы по мониторингу KPI, автоматическим тестам качества ответов и процедурами отката, что обеспечивает контроль качества при запуске пилота.
Часто задаваемые вопросы
Каковы основные преимущества использования LLM в клиентском сервисе?
Использование LLM в клиентском сервисе позволяет значительно повысить качество обслуживания за счет улучшенной персонализации и последовательности ответов. LLM могут обрабатывать большие объемы данных и извлекать релевантную информацию из долговременной памяти, что помогает избежать потери контекста в длительных взаимодействиях. Это приводит к сокращению времени решения запросов и повышению удовлетворенности клиентов, что, в свою очередь, способствует увеличению лояльности и удержанию клиентов.
Как выбрать подходящую векторную базу данных для автоматизации?
При выборе векторной базы данных для автоматизации обслуживания клиентов важно учитывать такие факторы, как масштабируемость, производительность и требования к latency. Необходимо оценить, как база данных будет обрабатывать объемы данных, а также ее способность к быстрому обновлению индексов. Рекомендуется проводить тестирование на пилотных проектах, чтобы убедиться, что выбранная база данных соответствует требованиям вашего бизнеса и обеспечивает необходимую производительность.
Каковы основные метрики для оценки эффективности клиентского сервиса?
Основные метрики для оценки эффективности клиентского сервиса включают CSAT (удовлетворенность клиентов), NPS (индекс лояльности), CES (усилие клиента) и FCR (решение при первом контакте). Каждая из этих метрик предоставляет уникальную информацию о взаимодействии с клиентами и помогает выявить области для улучшения. Регулярный мониторинг этих показателей позволяет компаниям адаптировать свои стратегии и повышать качество обслуживания.
Как автоматизация влияет на затраты на обслуживание клиентов?
Автоматизация обслуживания клиентов может значительно снизить затраты, так как позволяет уменьшить время, затрачиваемое на решение запросов, и снизить нагрузку на сотрудников. Использование LLM и чат-ботов для обработки рутинных задач позволяет операторам сосредоточиться на более сложных запросах, что повышает общую эффективность. В результате компании могут сократить расходы на поддержку и одновременно улучшить качество обслуживания.
Как обеспечить безопасность данных при использовании LLM и автоматизации?
Обеспечение безопасности данных при использовании LLM и автоматизации включает в себя внедрение шифрования, контроля доступа и регулярного аудита действий. Важно также следить за соблюдением нормативных требований, таких как GDPR, и обеспечивать защиту персональных данных клиентов. Компании должны разрабатывать четкие политики безопасности и обучать сотрудников правильному обращению с данными, чтобы минимизировать риски утечек и несанкционированного доступа.
Каковы основные шаги для успешного внедрения LLM в клиентский сервис?
Основные шаги для успешного внедрения LLM в клиентский сервис включают диагностику текущих процессов, определение целевых KPI, проектирование архитектуры памяти и выбор технологий. После этого следует запуск пилотного проекта, сбор и анализ метрик, а затем масштабирование успешных решений. Такой поэтапный подход позволяет минимизировать риски и адаптировать стратегии на основе фактических данных и результатов.
Заключение
Оптимизация клиентского опыта с помощью LLM и автоматизации значительно повышает удовлетворенность клиентов и эффективность бизнеса. Внедрение стратегий, основанных на четких метриках, позволяет достичь стабильных результатов и улучшить взаимодействие на всех уровнях. Начните с нашего пошагового плана, чтобы реализовать эти изменения в своей компании. Узнайте больше о том, как наши решения могут помочь вам достичь успеха в обслуживании клиентов.

Comments